业务安全ABC
差分隐私
英文名Differential privacy
1 概要
原则和实例
2 正式的定义和应用示例
灵敏度
准确性与隐私的均衡
差分隐私的其他概念
3 差分隐私机制
拉普拉斯机制
Netflix奖
医疗数据库事件
元数据与流动数据库
4 采用差分隐私的实际应用
概要
差分隐私Differential privacy[1] 是对通过算法消除的个人隐私的数学定义。当个人信息用于创建数据产品时通过某种方法可以消除特定的个人隐私信息。该术语由Cynthia Dwork于2006年创造[2] ,但更早的定义实际上来源于Dwork,Frank McSherry,Kobbi Nissim和Adam D. Smith 的文章[3] 。差分隐私的概念部分基于Nissim和Irit Dinur 的工作[4] ,他们的研究表明,即使通过大量统计发布的数据,也一定会泄露个人信息;而且通过少数查询就可以获取整个数据库的信息。
Dinur和Nissim的“数据库重建”工作的是人们认识到使用隐私的语义定义为统计数据库提供隐私保护的方法是不可行的。而且随着私人数据在统计数据中的增长,需要新的科技帮助人们控制隐私泄露的风险。后续研究工作的结果是技术的发展使得在许多情况下可以从数据库提供非常准确的统计数据,同时仍然确保高度的隐私性。[2]
原则和实例
差分机密性是将随机性引入数据的过程。
一个社会学简单的例子,[6] 根据以下流程要求被提问者回答“你拥有属性A?”的问题,对方的回复流程是:
1. 扔一枚硬币。
2. 如果正面朝上,然后诚实回答。
3. 如果反面朝上,然后再扔硬币,如果正面回答“是”,如果反面回答“否”。
保密性来源于个人答复的可纠正性。
但总的来说,这些有很多答案的数据是非常重要的,因为没有属性A的人给予四分之一的肯定答案,实际拥有属性A的人给出四分之三的肯定答案。如果p是A的真实比例,那么我们期望得到(1/4)(1-p)+(3/4)p =(1/4)+ p / 2的肯定答案。因此可以估计p。
特别是如果属性A可能意味着非法行为,因为无论是否违法的具体个人都有可能给出“是”的答案回应,那么回答“是”不会获罪。
虽然受随机响应启发的这个例子可能适用于微数据(即释放单独响应的数据集),但根据定义,差分隐私排除了微数据发布,并且仅适用于查询(即,将单个响应合并为一个结果)。微数据发布因为可以抵赖个人数据的存在性而不符合差分隐私的定义。[7-8]
正式的定义和应用示例
假设
 是一个正实数,A是一个随机算法,它将数据集作为输入(表示信任方拥有的数据)。imA表示A的映射。对于在非单个元素(即,一个人的数据)的所有数据集D1和D2以及imA的所有子集S,算法A是
-差分隐私,其中概率取决于算法的随机性。
是一个正实数,A是一个随机算法,它将数据集作为输入(表示信任方拥有的数据)。imA表示A的映射。对于在非单个元素(即,一个人的数据)的所有数据集D1和D2以及imA的所有子集S,算法A是
-差分隐私,其中概率取决于算法的随机性。
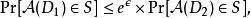
例如, 假设我们有一个医疗记录数据库 D1 在那里每条记录是一对 (名字, x), 其中 X 是一个布尔值表示一个人是否痪有糖尿病。例如:
姓名 有糖尿病 Ross 是1Monica 是1
Joey 否0
Phoebe 否0
Chandler 是1
现在假设一个恶意用户 (通常被称为攻击者) 想知道Chandler是否有糖尿病。假设他知道Chandler在数据库的哪一行。现在攻击者只能使用特定形式的查询Qi返回数据库中前i行中第一列 X 的部分总和。攻击者为了获取Chandler是否有糖尿病的信息。只需要执行两个查询 Q5(D1)和Q4(D1),分别计算前五行和前四行的总和,然后计算两个查询的差别。在本例中Q5(D1)=3,Q4(D1)=2,差是1。攻击者在知道Chandler在第5行的情况下,就会知道他的糖尿病状况是1(有糖尿病)。这个例子显示了即使在没有明确查询特定个人信息的情况下, 个人信息如何被泄露。
继续这个例子,如果我们用(Chandler,0)代替(Chandler,1)构造D2,那么这个恶意攻击者将能够通过计算每个数据集的Q5-Q4来区分D2和D1。 如果攻击者被要求通过
-差分隐私算法接收Qi值,对于足够小的
,则他将不能区分这两个数据集。
灵敏度
d为正整数,D为一个数据集的集合,
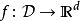 为函数。
为函数。
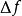 代表的函数的灵敏度[9] 由下式定义:
代表的函数的灵敏度[9] 由下式定义:
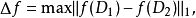
其中最大值是D中的所有对数据集对应的D1和D2中最差别最大的一对,
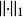 表示曼哈顿距离。
表示曼哈顿距离。
在上面医学数据库的例子中,如果我们认为f是函数Qi,那么函数的灵敏度就是1,因为改变数据库中的任何一个条目都会导致函数的输出改变0或å1。
有一些技术(如下所述),我们可以使用这些技术建立低灵敏度差分隐私算法。
准确性与隐私的均衡
通过差分隐私加扰的结果,要在统计数据的准确性和隐私参数之间有权衡.[10-13] 这种均衡也必须考虑到ε参数乘以查询数量(包括预计的查询数量)。
差分隐私的其他概念
对很多应用而言, 差分隐私被认为过于严格, 因此建议了许多被弱化的版本。这些包括 (ε, δ)-差分隐私,[14] 随机差分隐私, [15]以及特定标度的隐私。[16]
差分隐私机制
由于差分隐私是一个概率概念,任何差分隐私机制必然是随机的。下面描述的拉普拉斯机制就依赖于我们对结果添加的受控噪声。 其他的像指数机制[17] 和后验抽样[18] 依赖于问题的分布族。
拉普拉斯机制
许多差分隐私方法以添加受控噪音实现降低查询结果的灵敏度[9] 。拉普拉斯机制增加了拉普拉斯噪声(即符合拉普拉斯分布的噪声,其可以用概率密度函数
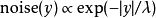 表示,其均值为0和标准偏差是
表示,其均值为0和标准偏差是
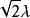 )。现在在我们的例子中,我们将的输出函数定义为实值函数(称为
)。现在在我们的例子中,我们将的输出函数定义为实值函数(称为
 的输出副本)为
的输出副本)为
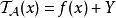 ,其中
,其中
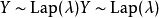 和f是我们计划在数据库上执行的原始实值查询/函数。现在很明显,
和f是我们计划在数据库上执行的原始实值查询/函数。现在很明显,
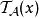 可以被认为是一个连续的随机变量,其中
可以被认为是一个连续的随机变量,其中
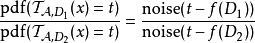 ,最多为
,最多为
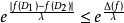 .我们可以认为是隐私因子
。 因此,
.我们可以认为是隐私因子
。 因此,
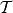 遵循不同的隐私机制(从上面的定义可以看出)。 如果我们试图在我们的糖尿病例子中使用这个概念,那么从上面推导出的事实可以看出,为了让
作为
-差分隐私算法,我们需要
遵循不同的隐私机制(从上面的定义可以看出)。 如果我们试图在我们的糖尿病例子中使用这个概念,那么从上面推导出的事实可以看出,为了让
作为
-差分隐私算法,我们需要
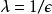 。 虽然我们在这里使用了拉普拉斯噪声,但也可以使用其他形式的噪声,例如高斯噪声,但这样可能需要略微放宽差分隐私的定义[19] 。
。 虽然我们在这里使用了拉普拉斯噪声,但也可以使用其他形式的噪声,例如高斯噪声,但这样可能需要略微放宽差分隐私的定义[19] 。
设想一个受信任的机构持有涉及众多人的敏感个人信息(例如医疗记录、观看记录或电子邮件统计)的数据集,但想提供一个全局性的统计数据。这样的系统被称为统计数据库。但是,提供有关数据的综合性统计也可能揭示一些涉及个人的信息。事实上,当研究人员链接两个或多个分别无害化处理的数据库来识别个人信息时,各种公共记录匿名化的特殊方法都失效了。而差分隐私就是为防护这类统计数据库脱匿名技术而形成的一个隐私框架。
Netflix奖
举例来说,2006年10月,Netflix提出一笔100万美元的奖金,作为将其推荐系统改进达10%的奖励。Netflix还发布了一个训练数据集供竞选开发者训练其系统。在发布此数据集时,Netflix提供了免责声明:为保护客户的隐私,可识别单个客户的所有个人信息已被删除,并且所有客户ID已用随机分配的ID [sic]替代。
Netflix不是网络上唯一的电影评级门户网站,其他网站还有很多,包括IMDb。个人可以在IMDb上注册和评价电影,并且可以选择匿名化自己的详情。德克萨斯州大学奥斯汀分校的研究员Arvind Narayanan和Vitaly Shmatikov将Netflix匿名化的训练数据库与IMDb数据库(根据用户评价日期)相连,能够部分反匿名化Netflix的训练数据库,危及到部分用户的身份信息。
医疗数据库事件
卡内基梅隆大学的Latanya Sweeney的将匿名化的GIC数据库(包含每位患者的出生日期、性别和邮政编码)与选民登记记录相连后,可以找出马萨诸塞州州长的病历。
元数据与流动数据库
MIT的De Montjoye等人引入了单一性(意为独特性)概念,显示出4个时空点、近似地点和时间就足以唯一性识别一个150万人流动数据库中的95%用户。该研究进一步表明,即使数据集的分辨率较低,这些约束仍然存在,即粗糙或模糊的流动数据集和元数据也只提供很少的匿名性。
采用差分隐私的实际应用
迄今已知的微分隐私的几个应用:
美国人口普查局为显示交通状况[21]
谷歌的RAPPOR[22]
谷歌,共享历史流量统计[23]
2016年6月13日,苹果宣布打算在iOS 10中使用差分隐私[24]
在数据分析和反欺诈中,差分隐私的一些初步研究[25] 。


关注我们

关注人人云图微信公众号
为您的业务保驾护航