业务安全ABC
业务安全中数据科学的基本概念
十里不同音,百里不同俗。 如果您听两个潮汕人喝早茶,基本只能听到发音,但是既不知道在说啥,也不知道哪个词什么意思。现代科学的高速发展,使得我们都用普通话在讲陌生专业的的时候也几乎无法交流。我能听懂钟南山院士说的每个字,但是完全不懂他在说啥,只是听着很高端的样子。
我们是以“数据科学”作为技术底座的安全公司,我们的科学家,算法工程师,软件工程师,产品,销售都需要理解我们的和传统网络安全的区别,统一我们的技术名词和基本话术。未来我们的团队越来越大,越来越专业,市场,媒体,甚至行政财务需要弄懂数据科学的基本概念和定义。
解决问题的方法很简单-通过学习把我们拉到一个叫“数据科学”的语言空间。 由于我们使用了 多层次自标注人机识别算法 (现在是一个广告用语,未来我们努力把它变成行业通识),我基于反欺诈和人机识别介绍下业务安全种常遇到的几个数据科学的概念。
模型: 模型是对客户业务问题的数学抽象描述。 从理论上讲,它涵盖了将数据分成组或“类”或预测输出值(高度,重量,成本等)的一系列数学方法。 这些复杂程度不一,但实用的方法可以通过给定旧数据获取预测新数据的数学规则。
模型的的另一种意思是是表示执行这些训练和规则的软件-吸收新数据并输出表示判定结果的数据,比如:认为新数据属于某个组(比如是人还是机器)的概率,或认为合适的预测输出值的可运行代码。常见的通用模型有决策树、逻辑回归、朴素贝叶斯、神经网络等等,实际业务中的模型,都是以这些通用模型为基础,加以组合或变化而来的。
标注: 把数据拿来,手工或者自动给他分类或者记录结果数值。
分类器: 分类器是一类常见的模型。通常意义的分类器指的是解决分类问题的模型。典型的分类问题比如判定这些请求来自真人还是机器,当前信用卡用户属于真实用户还是欺诈用户等。
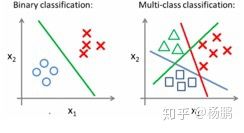
预测器: 通常意义的预测器指的是解决回归问题的模型。典型的回归问题比如预测当前用户后续的订票概率,当前用户后续的支付概率等。
分类: 将数据分成组或“类”或分级(离散的分,比如好中差,或者1,2,3,4,5分)的建模技术叫分类。使用分类的模型也叫分类器。
回归: 回归分析是一种自动寻找数据之间对应关系的建模技术,它研究的是因变量(目标)和自变量(预测器)之间的关系。比如信用卡开卡用户前三次消费数额和后续平均每个月消费数额之间的对应关系。
特征/维度: 特征是模型的输入数据。维度这个词很流行,听上去比较高端大气上档次,其实特征更贴切一些,低调奢华有内涵。数据科学很多时候就是特征工程,比如预测建筑物是否会在未来10年内烧毁的模型,可以用的特征数据有,建筑物的年龄,建筑物的类型以及居住者是否吸烟等特征。 并非所有数据都和模型相关,有些数据可能和我们做的预测/分类没有半毛钱关系,白白增加复杂性。
训练: 正如李小龙需要时间和精力来完善自己的技能一样,模型也需要大量数据和时间来自动学习如何识别真人和机器爬虫,欺诈用户和正常用户。用于训练的数据集合叫训练集。
测试/验证: 给经过训练的模型提供新的数据,来看模型的性能,叫做测试或者验证。用于测试的数据叫测试集或者验证集。
准确率/准确度/精度: 通常指的是衡量模型结果与真实结果的接近程度的度量。 由于很难知道未来的“真实结果”,这个结果通常是我们用验证集来部分验证的。 假设我们有1000个验证样本,其中包括800个应当被识别出的目标,以及200个并非目标的干扰数据。模型识别出900个目标,其中有720个确实是我们预设的目标,还有180个是将干扰数据识别成了目标。这里准确率就是720/900=80%。对于同一个模型,召回率和准确率的提高往往是互相矛盾的目标,提高一个常常导致另一个降低。因此这两个指标也是可以互相调整的,召回率越高,准确率就很难保证,召回率要求不高,准确率就容易得到保证。
回归率/召回率: 衡量模型中对于多少样本可以做出科学回归或者分类的度量。 在上例中,模型的召回率是720/800=90%。与召回率相对应的一个业务上常提到的指标是漏报率,90%的召回率对应的漏报率就是10%。召回率和准确率是可以互相调整的,有的反欺诈场景要求一个疑似的都不能放过,那么这个时候我们就要高召回率,低准确率。有的业务安全场景要求高准确率不能误杀引起客户投诉,那么我们就要力保准确率,对于召回率只能佛系提高了。
几个进阶版概念,我列出来,有兴趣的小伙伴自己随缘:
决策阈值: 在业务安全的场景下,对于绝大多数情况下,只需要分出来好中差,或者正常/欺诈用户,这些分级的设定标准,就是决策阈值。设置得太高,可能模型有效性会出问题。 将其设置得太低,对客户的业务指导意义不大。 准确度测量是在选择阈值之后进行的。 更改阈值会大大改变准确度。
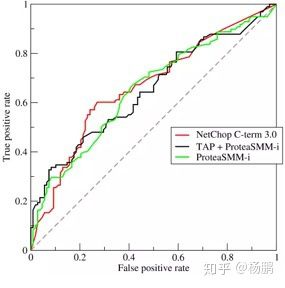
AUC(曲线下面积) 此数字的范围是0.5(差)至1(好)。 越接近1,模型的性能越好。 这与准确性类似,但考虑到选择决策阈值的微妙性质。
ROC曲线: 某种反应准确率,误判率,召回率,决策阈值之间关系的曲线,这几个数是辩证统一的。 数据科学不是万能的,追求某一种性能,就要牺牲其他性能。通常算法工程师会根据业务场景做折衷取舍。
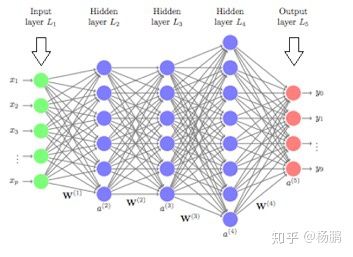
神经网络: 模拟人脑神经节的一种模型算法,实践效果在有些领域不错。但是通常结果不太能解释,使用受限制。

深度学习: 面对海量数据,尤其是海量特征/维度数据的时候,使用深度学习实现多层的神经网络(一般几十层)。当前只有图像和视频识别有较好的效果,深度学习的发展使得人脸识别/车牌识别等计算机视觉场景实现了工业化应用的可能。谁要跟你在图像和语音以外的场景吹逼深度学习,他可能用的是3-5层的CNN神经网络,用的顺手了而已,并不会比简单的可解释模型精度高。
朴素贝叶斯: 基于古典统计学和概率论的分类模型。跟据输入到输出的联合概率分布做出分类。
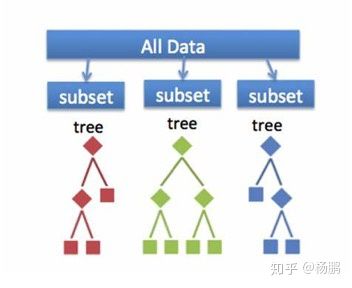
决策树: 可以简单的理解,通过多层次的逻辑决策,像树一样能够做出分类就叫决策树,是一种非常重要的分类模型,决策树的高级版本叫随机森林。
随机森林: 很多的决策树,通过训练能够分配不同的权重给不同的决策树就叫随机森林,是一种非常重要的分类模型。


关注我们

关注人人云图微信公众号
为您的业务保驾护航